Datalog是什么
Datalog是一种数据查询语言,专门设计与大型关系数据库交互,语法与Prolog相似。Datalog的语法是Prolog的子集,但是Datalog的语义与Prolog不同。Datalog是一种声明式的语言,Declarative(声明式)语言主要有SQL等,其屏蔽细节,因此代码量更小,可读性更强。
Datalog=Data+Logic(and,or,not) 其特性为:
- 没有副作用(不会更改已有数据)
- 没有控制流
- 没有函数
- 不是图灵完备的
Datalog语法
Data部分
Predicates(谓词)
谓词(Predicates)是datalog中的一个主要组成部分,可以看作是数据所组成的一个表(table of data),每一行都代表一个事实(fact)。
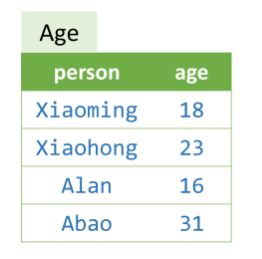
在上述表中,Age就是个谓词,在Age中(‘xiaoming’, 18)就是个事实,而(‘xiaohong’, 18)不存在,就不是个事实。
Atoms
atoms分为两种:关系型原子(relational atom)和算术型原子(arithmetic atoms)。 算数型原子由算数表达式组成,例如age >= 18
关系型原子由谓词名称(name of predicates)和参数(arguments/terms)组成,例如P(X1,X2…Xn),P表示谓词名称,(X1,X2,…Xn)表示参数。参数可以有两种形式:变量和常量。例如Age(person, age)列出Age中所有的事实,Age(‘xiaoming’, 18)列出小明18岁这个事实。
Logic部分
Rules
Datalog使用规则来进行推导,H <- B1, B2, … ,Bn就是一个rules,其中H是一个atom,B1,B2…Bn表示前提条件,Bi表示子目标,逗号表示逻辑与。这个rules表示当B1、B2一直到Bn这些子目标都成立,H才能成立,本质上是霍恩子句。

求解过程(Interpretation of Datalog Rules)——枚举Body中所有关系表达式的可能取值组合,进而得到新的predicate/table。例如:

枚举Age中的事实,找到满足age >= 18的事实,组成新的谓词Adult。

对于谓词,分为两类EDB和IDB:
- EDB(extensional database):在程序运行前,这些数据已经给定。例如上述的Age。
- IDB(intensional database):由规则推导而来。例如上述的Adult。
Logic
And
上面也提到过,逗号表示逻辑与。
Or
逻辑或则有两种实现方式:
编写多条推到规则,但是Head要相同。例如:
1 2
SportFan(person) <- Hobby(person, "jogging"). SortFan(person) <- Hobby(person, "swimming").
使用 ; 分隔
1SportFan(person) <- Hobby(person, "jogging");Hobby(person, "swimming").
or的优先级低于and,组合运用时要注意优先级,必要时要使用括号。
Not/Negation
! 表示非,例如找出不喜欢慢跑的人:
1
| SportFan(person) <- !Hobby(person, "jogging"). |
Recursion
1 2 | Reach(from, to) <- Edge(from, to). Reach(from, to) <- Reach(from, node),Edge(node, to). |
Datalog支持递归调用,例如可达性分析,如果from跟to之间有边连接,则from可达to。如果from跟to没有直接的边进行连接,就可以枚举from可达的node,再判断node到to之前是否存在边。
Rule Safely
现有两条有问题的rules:
1 2 | A(x) <- B(y), x > y. A(x) <- B(y), !C(x,y). |
由于x有无限的取值能满足规则,所以生成的A是一个无限大的关系。因此上述两条规则是不安全的。在Datalog中,只接受安全的规则。
如果规则中的每个变量至少在一个non-nageted relational atom中出现一次,那么这个规则是安全的。 因为已有的谓词中的事实是有限,通过这个性质来限制变量的取值范围。
1
| A(x) <- B(x), !A(x) |
假设B(x)为真,如果Head中的A(x)为真,那么body中的A(x)就要为假;如果Head中的A(x)为假,那么Body中的A(x)就要为真。互相矛盾了,所以不要把recursion和negation写在同一条规则里。
执行
Datalog输入EDB和Rules,经过Datalog engine不断推导,最终产生IDB。
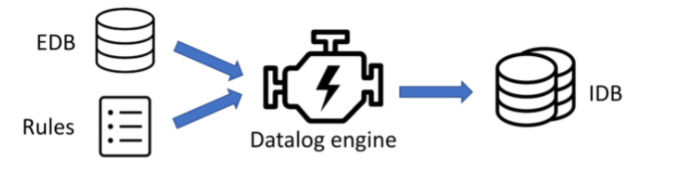
Datalog engine有不同语言的实现,例如LogicBox, soufflé等。 所以Datalog有两大重要特性:
- 单调性。因为事实(facts)不会被删除的。
- 必然终止。
- 事实的数量是单调的。
- 由Rule Safety,所能得到的IDB的大小也是有限的。
应用
Pointer Analysis via Datalog
EDB
根据指针分析的几种行为(先排除call,在call graph中进行分析):
定义变量集合为 V,域为 F,对象为 O。
所以就有:
1 2 3 4 | New(x : V, o: O) // 存在x变量与o对象这一对事实 Assign(x : V, y : V) // x变量与y变量这一对事实 Store(x : V, f : F, y : V) Load(y : V, x : V, f : F) |
IDB
1 2 | VarPointsTo(v: V, o: O) // o 属于 pt(v) FieldPointsTo(oi: O, f: V, oj: O) // oj 属于 pt(oi.f) |
rules
根据先前指针分析部分中定义的规则:
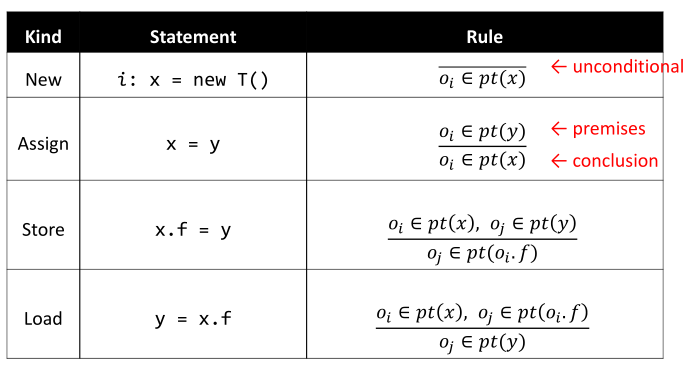
组合上述IDB与EDB,就能得出Datalog的rules:

纸上运行
根据例子,将EDB中的事实填充好:

处理New语句,得到部分VarPointsTo:

因为VarPointsTo中存在事实了,就可以进行递归了,下一步处理Assign:

处理Store:
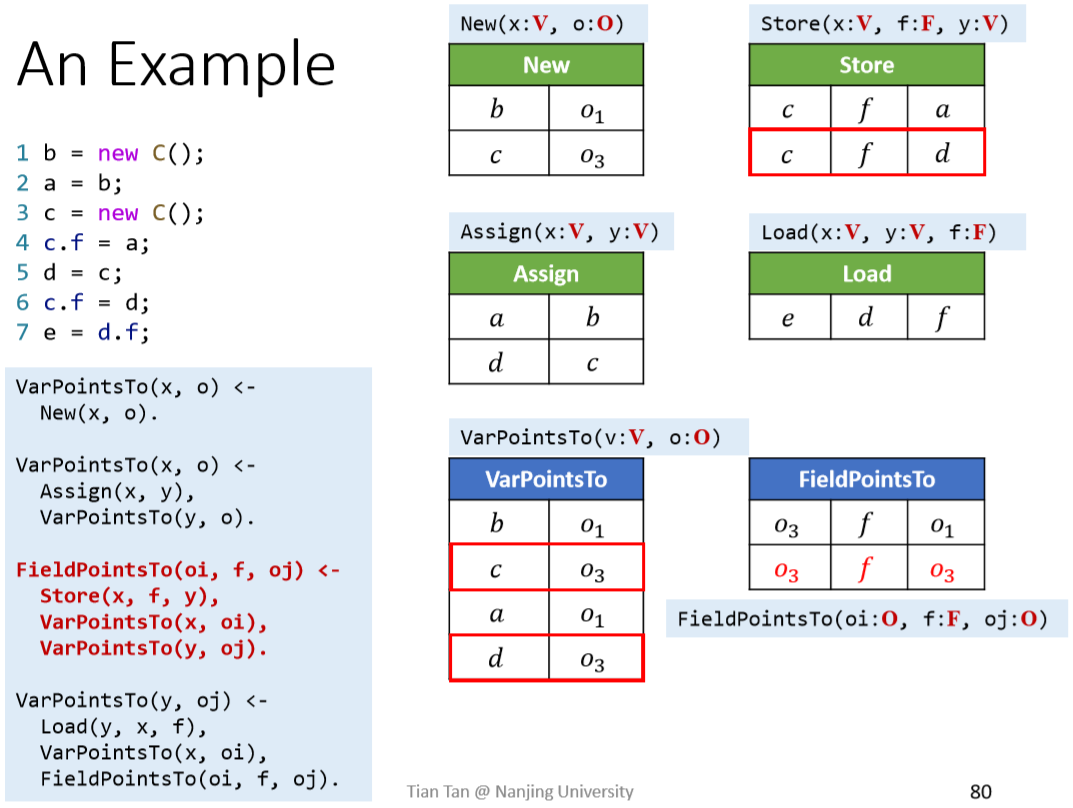
处理Load:
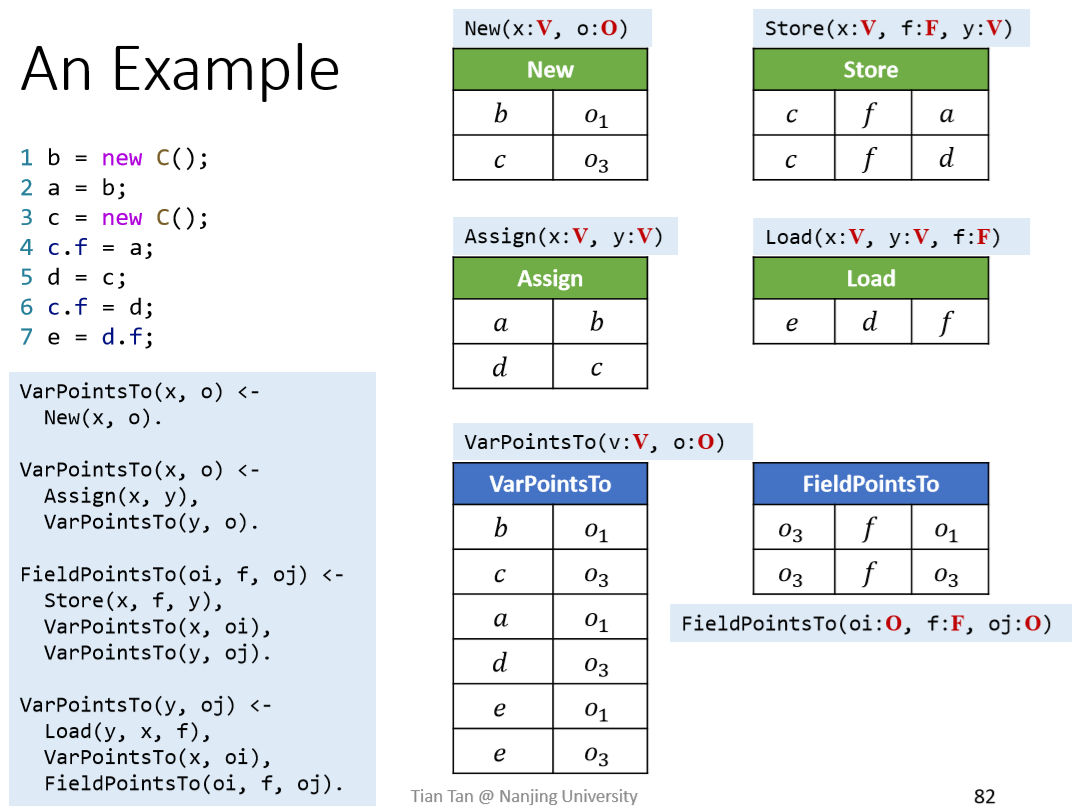
如果不能产生新的事实,就退出程序。实际情况下,Datalog engine不一定是这样按顺序推导,只要能够产生新的事实的rules,就能进行推导。
其他应用
例如call graph分析,请参考:
https://spa-book.pblo.gq/ch4/04-02-datalog-based-pa